Hacking The 3ds II: Finding the Pattern
Hello again!
I’m back with part 2: “Finding The Pattern”! In case you haven’t read yet the first blog entry, click here.
Brief Summary
Back in the day, I analysed what possible entry-points the 3DS may have. We lead to the conclusion that the RAM contents were not encrypted. This is something useful. Here's proof:
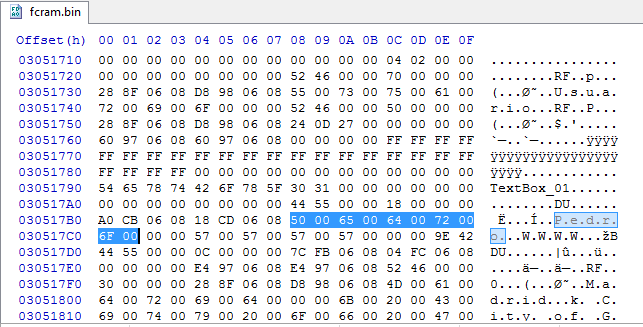
Unicode string found in the RAM Dump.
As you can see, if we search for unicode strings (remember the 3DS supports several languages, as everything should do this days, to enable non-ascii languages to work, i.e. Japanese, Spanish, etc.) we can find that they are in plaintext.
Side-Note: I searched for known strings, such my profile username and folder names.
The Dumps
So, we can find strings. But that's not really useful by itself, is it?
Before trying anything, we should have some knowledge about how modern systems manage and map memory.
1. Virtual Memory:
Every computer, phone, machine, that is a little up-to-day supports the concept of "multi-applications"; This means basically that several applications or services are running AT THE SAME TIME, using THE SAME SHARED RESOURCES, more or less, because that would be a total mess. Imagine if any application could access and modify any other process information. Since we can't split physical memory, the concept of virtual memory was invented. Briefly, when the kernel is told to start a given process, it will spawn it in an "emulated" environment; The new process would see and believe that it is running as if it were running normal, being able to access any memory address. That's actually not true, it can access any address, but in fact those addresses are mapped by the kernel to physical memory. So for the sake of this small explanation, we'll say that the process would believe he is running as normal and as if no other processes were running at the same time. "Completely" Isolated.
2. Memory Pages Location:
Not only pages the kernel the virtual memory to physical memory, but also places it into the hard disk (and other storages depending on the platform). This means, if we were "viewing" all the memory in a picture, it's possible that our data would be stored in different parts of the memory and HDD, not all close together.
3. Memory Pages Types:
Still, it's not that simple. There's a protection called DEP (Data Execute Prevention) or NX bit (No eXecute) which does the following. You could, using a simple buffer overflow vulnerability, write your own code to the memory (at any page, for example, or even unallocated memory) and then jump to it, gaining unsigned code execution. DEP basically adds a flagging/privilege system to pages. Back in the time, pages were all WX, writable(W) and executable(X) at the same time. With DEP (or, in the same words, NX bit activated) pages can only be writable, or only executable, but not both at the same time. This means, that even you could write to a writeable page, you couldn't execute that code, at the same time you can't write to executable pages. But don't worry, as always, there's ways to bypass this, but they are out of the scope of this blog post. The point here is you to know that, assuming DEP is enabled, we can difference between data and code pages, since data pages will only contain data, and vice-versa.
Finding The Pattern
Unicode string found in the RAM Dump.
So. Ok. We know now more about how the system could work. And we have RAM dumps. There’s a few ideas I’ve come up with.
What if we could identify and extract the different kind of memory pages that were loaded when we took the dump?
We now can; Entropy is the key. What’s entropy you may be asking? Entropy is the measure of randomness. Sounds cool, doesn’t it? But how is this supposed to help us identifying pages? Well, just think about it this way: processor designers trying to pack instruction definitions as effective as possible, but programmers never trying to store data efficiently.
We lead then to the conclusion that memory pages marked as executable, which will surely contain code, will have a higher entropy
On the other hand, pages marked as writeable, which will surely contain application data, will have a low entropy.
Let’s now try to measure the entropy of our RAM dumps. I can’t upload them because they contain copyrighted/protected code and data from N, but I’ll later explain how to get your own full software dumps (4.X firmware only). For this task, I’ll use http://binvis.io a webpage to compare entropy (and other data) from binary files. (NOTE: Binvis actually runs on your browser so files are kept and not sent to any server. You can reverse your stuff calmly)
 First glance at the RAM Dump. Byte class view.
First glance at the RAM Dump. Byte class view.Since I took the dump with little applications running, we can expect a lot of unallocated memory (0x00).
As for everything else, this view isn’t much interesting. Let’s move to entropy view:
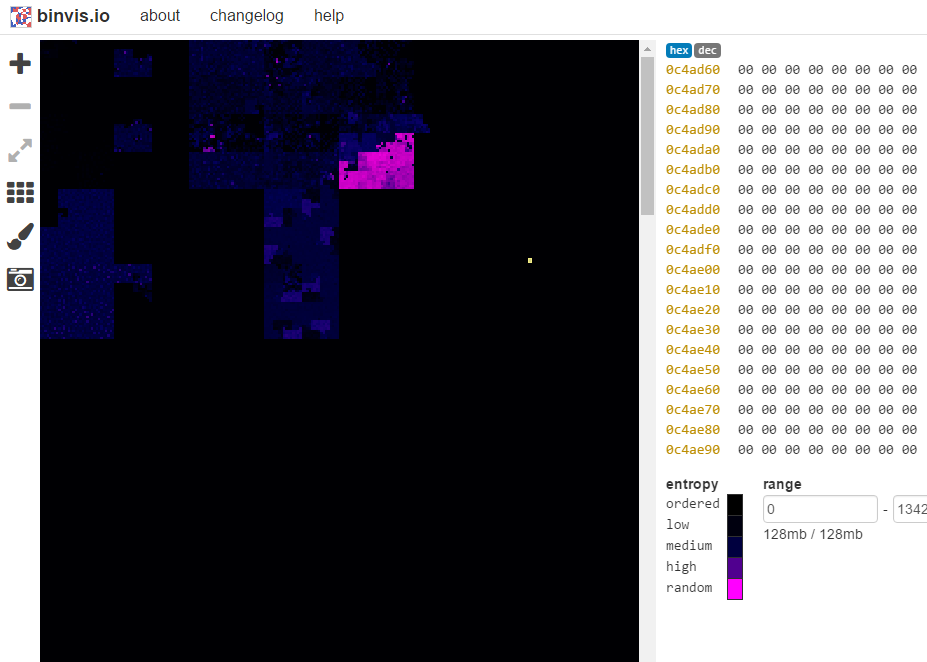 Ahhh… This looks much more promising.
Ahhh… This looks much more promising.If we look further into the pink sections (higher entropy) we can’t identify any kind of string or anything that makes sense to an human. That looks like code!
This picture above shows the chunk(cluster) view mode, that shows blocks with same entropy. For a more realistic view, we can switch to linear(scan) mode.
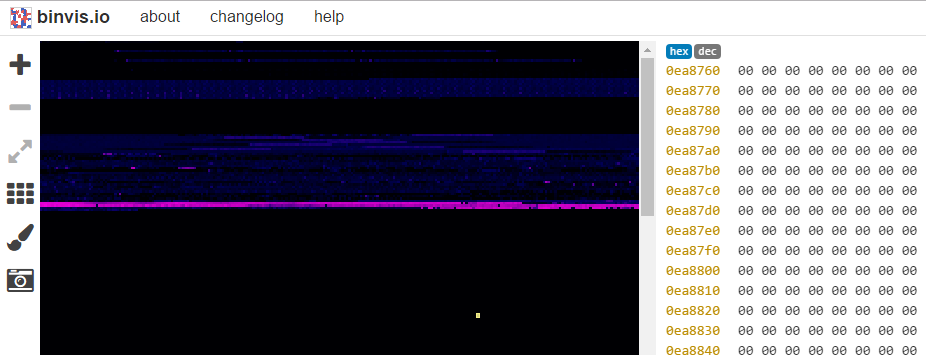 Code identified
Code identifiedLet’s try doing some zoom (with the + icon obviously). I move to the “start” of the binary and we can see this!
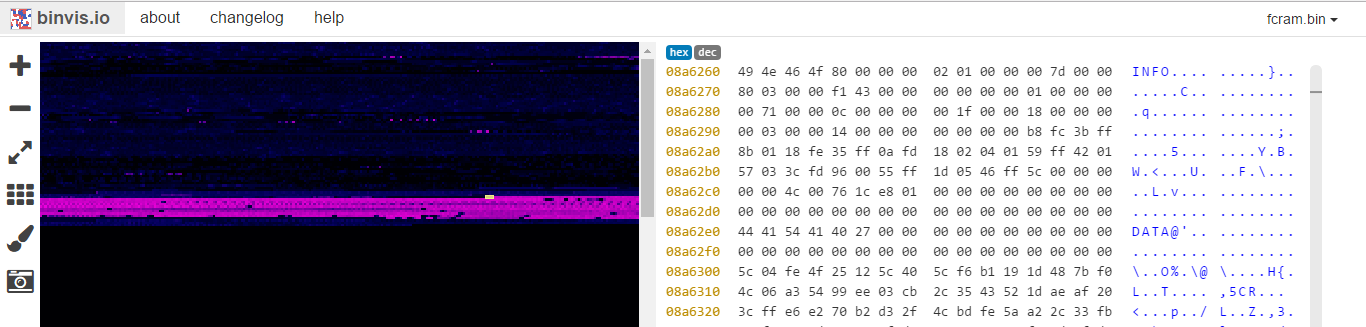 We can also find what looks like section identifiers
We can also find what looks like section identifiersThis may be what we were searching for!
Code is not the only stuff with high entropy; JPEG compressed images, or encrypted data, will have high entropy too.
Now, repeat this for all the high-entropy chunks; take note of those addresses (more or less, start and end, I’ll go in depth with this in other post.), grab your favourite file manager and extract that precious piece of code.
When a program is executed, usually not the whole binary is loaded into memory, only important sections are loaded so don’t expect to find the whole binary in memory, nor headers or things like that, despite we could find them sometimes.
Conclusions
In this entry, I’ve shown briefly a way to extract pages of code (and surely other stuff).
In the next post, I’ll identify code pages and try to reverse them!
As for now, special thanks to:
-@nicowaisman: Great person and hacker/reverser. First idea about scanning memory.
-@ws: The idea to compare entropy was mainly his; Also helped with other minor stuff.
-@cortesi: Creator of binvis, great support too :)
-@GovanifY: Replied all my emails, and he is a great scener, despite what people may think.